 Minotauromaquia
Minotauromaquia
Amazon's Web Services (AWS), en in het bijzonder de Simple Storage Service (S3)[1] worden door veel mensen en bedrijven op grote schaal gebruikt om hun gegevens, websites en backends te beheren. Deze variëren van geïsoleerde personen en kleine startups tot waardemaatschappijen met meerdere miljarden dollar, zoals Pinterest[2] en (voorheen) Dropbox.[3] Deze pagina is niet bedoeld als een gids voor onboarding S3; je kunt veel andere dergelijke gidsen online vinden.[4] Het is eerder gericht op individuen en bedrijven waarvan de verwachte S3-kosten tussen de $ 10 per maand en $ 10.000 per maand liggen. Andere soortgelijke lijsten met tips zijn online beschikbaar.[5]
Deze pagina gaat ook niet in op andere soorten S3-optimalisaties, zoals het optimaliseren van bucket-, map- en bestandsnamen en de bewerkingsvolgorde, gericht op het maximaliseren van de doorvoer of het minimaliseren van latency. De meeste van deze optimalisaties hebben geen directe invloed op de kosten (positief of negatief). Bovendien zijn ze over het algemeen alleen relevant op een aanzienlijk grotere schaal dan de schaal die de doelgroep voor deze pagina waarschijnlijk zal bereiken. U kunt meer over dergelijke optimalisaties lezen in de officiële S3-handleiding[6] en elders.[7]
Deel een van de zes:
Een breed begrip van S3 krijgen
- 1 Begrijp uw S3-gebruik. S3 kan voor veel doelen worden gebruikt.
- Als een plaats om bestanden op te slaan voor live-weergave op websites, inclusief afbeeldingsbestanden[8] of een volledige statische website (meestal achter een CDN zoals Amazon CloudFront of CloudFlare).[9][10]
- Als een datameer, een plek voor gegevens die u gebruikt of genereert in uw toepassingen: in essentie wordt S3 de langetermijnopslag voor uw gegevens, waarbij uw aanvankelijk gegenereerde gegevens worden vastgelegd op S3 en verschillende toepassingen die vanuit S3 lezen , de gegevens transformeren en terugschrijven naar S3.[11][12][13]
- Als een "datawarehouse", een plaats om langetermijnback-ups van gestructureerde en ongestructureerde gegevens op te slaan die niet bedoeld zijn voor verdere actieve consumptie.
- Als een plaats om uitvoerbare bestanden, scripts en configuraties op te slaan die nodig zijn om nieuwe EC2-instanties te starten met uw toepassingen (of uw toepassingen bij te werken op bestaande exemplaren).
- 2 Begrijp de belangrijkste manier waarop S3 de kosten beïnvloedt. Nummers hieronder zijn bedoeld voor standaard opslag, waarschuwingen met betrekking tot andere vormen van opslag worden later besproken.[14] Alle kosten worden toegepast en afzonderlijk gerapporteerd voor elke emmer en elk uur; met andere woorden, als u uw gedetailleerde factureringsrapport downloadt, ziet u voor elke combinatie van bucket, uur en type kosten één regelitem.
- Opslagkosten: De kosten worden gemeten in opslagruimte vermenigvuldigd met tijd. U betaalt niet vooraf voor een toegewezen hoeveelheid opslagruimte. Telkens wanneer u meer opslagruimte gebruikt, betaalt u extra voor die extra opslagruimte gedurende de tijd dat u het gebruikt. De kosten kunnen daarom in de loop van de tijd fluctueren omdat de hoeveelheid gegevens die u hebt opgeslagen, is gewijzigd. Opslagkosten worden voor elk emmer elk uur apart gerapporteerd. De prijsbepaling varieert per regio, maar wordt binnen elke regio vastgesteld. Vanaf december 2016 bedragen de kosten 2,3 cent per GB-maand in US Standard (North Virginia) tot 4,05 cent per GB-maand in Sao Paulo.[14]
- Vraag prijzen aan: Voor standaardopslag bedragen de kosten voor PUT-, COPY-, POST- of LIST-aanvragen van $ 0,005 per 1000 verzoeken in Amerikaanse regio's tot $ 0,007 per 1000 verzoeken in Sao Paulo.[14] De kosten voor GET en alle andere verzoeken zijn een orde van grootte kleiner, gaande van $ 0,004 per 10000 aanvragen in alle Amerikaanse regio's tot $ 0,0056 per 10000 verzoeken. Houd er echter rekening mee dat de meeste kosten die aan een GET-aanvraag zijn gekoppeld, worden vastgelegd in de kosten voor gegevensoverdracht (als het verzoek buiten de regio wordt gedaan). Merk ook op dat voor prijsgegevens die in andere soorten opslag worden opgeslagen, de prijs van een verzoek iets hoger ligt. Een ander soort verzoek dat relevant wordt bij de bespreking van levenscyclusbeleidslijnen, is het levenscyclustransitie-verzoek (bijvoorbeeld het overschakelen van iets van standaardopslag naar IA of Glacier).
- Kosten voor gegevensoverdracht: Kosten zijn nul binnen dezelfde AWS-regio (beide S3 -> S3 en S3 -> EC2-instances), ongeveer 2 cent per GB voor gegevensoverdracht over regio's en ongeveer 9 cent per GB voor gegevensoverdracht naar externe AWS.
- Retrieval pricing: Dit is niet van toepassing op standaardopslag, maar is van toepassing op twee van de andere opslagklassen, namelijk IA en Glacier. Deze prijzen worden toegepast per GB voor de opgehaalde gegevens.
- 3 Begrijp de centrale rol van buckets bij het organiseren van uw S3-bestanden en het gebruik van "object" voor S3-bestanden.
- U kunt emmers maken onder uw account. Een bucket wordt geïdentificeerd door een string (de bucket-naam). Er kan slechts één bucket met een bepaalde bucketnaam in alle S3 zijn, bij klanten; daarom kunt u een bucketnaam mogelijk niet gebruiken als iemand anders deze al gebruikt.
- Elke bucket is gekoppeld aan een AWS-regio en wordt gerepliceerd over meerdere beschikbaarheidszones binnen die regio. De beschikbaarheidszone-informatie is niet beschikbaar voor de eindgebruiker, maar is een intern implementatiedetail dat S3 helpt om een hoge duurzaamheid en beschikbaarheid van gegevens te behouden.
- Binnen elke bucket kunt u uw bestanden direct onder de bucket of in mappen opslaan. Mappen hoeven niet te worden gemaakt of verwijderd. Als u een bestand opslaat, zal het automatisch 'mappen' voor het bestandspad tot stand brengen die zinvol zijn, als ze nog niet bestaan. Zodra er geen bestanden onder zitten, houdt de map automatisch op te bestaan.
- De manier waarop S3 de informatie opslaat, is als sleutelopslag: voor elk voorvoegsel dat geen bestandsnaam is, slaat het de reeks bestanden en mappen met die prefix op. Voor elke bestandsnaam wordt dit toegewezen aan het eigenlijke bestand. In het bijzonder kunnen verschillende bestanden in een emmer in zeer verschillende delen van het datacenter worden opgeslagen.
- S3 noemt de bestanden "objecten" en je kunt deze term tegenkomen wanneer je ergens anders over S3 leest.
- 4 Begrijp de verschillende manieren waarop u kunt communiceren met S3-bestanden.
- U kunt online bestanden uploaden en downloaden door in te loggen via een browser.
- Opdrachtregelprogramma's op basis van Python bevatten de AWS-opdrachtregelinterface,[15], de verouderde s3cmd[16] en recentere s4cmd[17].
- Als u Java of een andere taal gebruikt die is gebaseerd op de JVM (zoals Scala), hebt u toegang tot S3-objecten met behulp van de AWS Java SDK.[18]
- Implementatietools zoals Ansible en Chef bieden modules om S3-resources te beheren.[19]
- 5 Begrijp de voors en tegens van het omgaan met S3 en de verschillen met een traditioneel bestandssysteem.
- Met S3 is een beetje meer gymnastiek vereist (en draaitijd) om een globaal beeld te krijgen van de hoeveelheid gegevens die in een emmer of in submappen van die emmer wordt gebruikt. Dat komt omdat deze gegevens nergens rechtstreeks worden vastgelegd, maar eerder moeten worden berekend via recursieve zoekacties op sleutelwaarde.
- Het vinden van alle bestanden die overeenkomen met een regex kan een zeer dure operatie zijn, vooral wanneer die regex jokertekens bevat in het midden van de uitdrukking in plaats van aan het einde.
- Het is niet mogelijk om bewerkingen zoals het toevoegen van gegevens aan een bestand uit te voeren: u moet het bestand ophalen, het wijzigen en vervolgens het volledige gewijzigde bestand terugzetten (zie het punt later over de synchronisatiemogelijkheden).
- Het verplaatsen of hernoemen van bestanden omvat eigenlijk het verwijderen van objecten en het maken van nieuwe. Als u een map verplaatst, moet u alle onderliggende objecten verwijderen en opnieuw maken. Elke bestandsverplaatsing heeft betrekking op een GET- en een PUT-oproep, wat leidt tot hogere prijsverzoeken. Bovendien kunnen bewegende objecten duur zijn als de objecten worden opgeslagen in opslagklassen (Standard-IA en Glacier), waar ophalen geld kost.
- S3 ondersteunt bestandsgroottes tot 5 TB, maar regiooverschrijdende gegevensoverdracht kan verward raken voor bestandsgroottes van meer dan een paar honderd megabytes. De CLI gebruikt multipart-upload voor grote bestanden. Zorg ervoor dat als uw programma's omgaan met grote bestanden, ze werken via de meerdelige upload of de uitvoer splitsen in kleinere bestanden.
- S3 biedt geen volledige ondersteuning voor rsync. Er is echter een sync-opdracht (aws s3-synchronisatie in de AWS CLI en s3cmd-synchronisatie in s3cmd) die alle inhoud synchroniseert tussen een lokale map en een S3-map, of tussen twee S3-mappen. Voor bestanden die zowel in de bron- als in de bestemmingsmap voorkomen, kan deze identieke bestanden detecteren en gegevensoverdracht vermijden als de bestanden identiek zijn; het is echter niet zo efficiënt als rsync omdat het misschien een volledige overdracht moet uitvoeren als bestanden een klein beetje verschillen, terwijl rsync slechts een klein verschil verzendt voor zeer vergelijkbare bestanden. Het andere verschil met rsync is dat het van toepassing is op een hele map en dat bestandsnamen niet kunnen worden gewijzigd.
Tweede deel van de zes:
Gegevens zippen / comprimeren
- 1 Zorg ervoor dat u gegevens comprimeert waar dit is toegestaan door de vereisten van uw toepassing voordat u begint.
- Ontdek welke vormen van zip-en compressie compatibel zijn met de processen die u gebruikt om gegevens te genereren, en de processen die u gebruikt om gegevens te lezen en te verwerken.
- Zorg ervoor dat u zippen en compressie gebruikt voor uw grootste hoeveelheid gegevens, voor zover dit uw toepassing niet hindert. In het bijzonder zijn onbewerkte gebruikerslogboeken en gestructureerde gegevens op basis van gebruikersactiviteit de voornaamste kandidaten voor compressie.
- Over het algemeen bespaart compressie niet alleen op opslagkosten maar ook op overdrachtskosten (bij het lezen / schrijven van de gegevens) en kan uw applicatie zelfs sneller worden als upload / downloadtijd een groter knelpunt is dan lokale compressie / decompressietijd . Dit is vaak het geval.
- Om een voorbeeld te nemen, het converteren van grote gestructureerde databestanden naar het BZ2-formaat kan de opslagruimte doen dalen met een factor variërend van 3 tot 10; BZ2 is echter rekenintensief om te rippen en uit te pakken. Andere compressie-algoritmen om te overwegen zijn gzip, lz4 en zstd.[5]
- Andere manieren om de ruimte te verkleinen, zijn onder meer opslag op basis van kolommen in plaats van op rijen gebaseerde opslag en binaire indelingen (zoals AVRO) in plaats van door mensen leesbare formaten (zoals JSON) voor gegevensretentie op de lange termijn.[5]
- 2 Als het comprimeren van gegevens niet mogelijk is op het punt waar u het voor het eerst schrijft, overweeg dan om een alternatief proces uit te voeren om de gegevens opnieuw in te nemen en te comprimeren. Dit is over het algemeen een suboptimale oplossing en zeer zelden nodig, maar er kunnen gevallen zijn waarin dit relevant is. Als u naar een dergelijke oplossing kijkt, moet u de berekeningen zorgvuldig uitvoeren op basis van de kosten voor het opnieuw beheren en comprimeren van de gegevens en de totale hoeveelheid tijd die u van plan bent om de gegevens te bewaren.
Derde deel van de zes:
Opslagkosten optimaliseren
- 1 Begrijp de verschillen tussen de vier soorten S3-opslag.[14]
- Standaard opslag is het duurst voor opslag, maar is het goedkoopst en snelst voor het aanbrengen van wijzigingen in gegevens. Het is ontworpen voor een duurzaamheid van 99,9999999999% (meer dan een jaar, dat wil zeggen, dit is de verwachte fractie van S3-objecten die een jaar zal overleven) en beschikbaarheid van 99,99% (beschikbaarheid die verwijst naar de waarschijnlijkheid dat een bepaald S3-object op een bepaald moment toegankelijk is). ). Merk op dat het in de praktijk zeer zeldzaam is om gegevens in S3 te verliezen en dat er grotere risicofactoren zijn voor gegevensverlies dan gegevens die feitelijk uit S3 verdwijnen (deze grotere factoren omvatten het per ongeluk verwijderen van gegevens en iemand die kwaadaardig hackt in uw account om inhoud te verwijderen, of zelfs Amazon wordt gedwongen om je gegevens te verwijderen vanwege druk van overheden).[20]
- Reducedancy Storage (RRS) was tot 20% goedkoper dan standaardopslag en biedt iets minder redundantie. Mogelijk wilt u het voor veel van uw gegevens gebruiken die niet erg kritisch zijn (zoals volledige gebruikerslogboeken). Dit is ontworpen voor een duurzaamheid van 99,99% en een beschikbaarheid van 99,99%. Vanaf december 2016 gingen prijsverlagingen voor standaardopslag echter niet gepaard met overeenkomstige prijsverlagingen voor RRS, dus RRS is op dit moment even duur of duurder.[21][22]
- Standaardopslag - Infrequent Access (S3 - IA genoemd) is een optie die door Amazon in september 2015 is geïntroduceerd en de hoge duurzaamheid van S3 combineert met een lage beschikbaarheid van slechts 99%. Het is een optie voor het opslaan van lange-termijnarchieven die niet vaak hoeven te worden geopend, maar die, wanneer ze moeten worden geopend, snel moeten worden geopend.[23] S3 - IA wordt in rekening gebracht voor een minimum van 30 dagen (zelfs als objecten daarvoor worden verwijderd) en een minimale objectgrootte van 128 KB. Het is ongeveer half zo duur als S3, hoewel de exacte korting per regio verschilt.
- Glacier is de goedkoopste vorm van opslag. Glacier kost echter geld om uit archief te halen en weer beschikbaar te maken voor lezen en schrijven, met het bedrag dat u moet betalen, afhankelijk van het aantal opvraagverzoeken, de snelheid waarmee u de gegevens wilt ophalen en de grootte van de opgehaalde gegevens. Glacier-bestanden hebben ook een opslagperiode van minimaal 90 dagen: bestanden die voor die tijd zijn verwijderd, worden voor de rest van de 90 dagen na verwijdering in rekening gebracht.
- 2 Krijg een idee van hoe uw kosten groeien.
- In een use-geval waarin u een vaste set bestanden hebt die u regelmatig bijwerkt (waardoor oudere versies effectief worden verwijderd), zijn uw maandelijkse opslagkosten ongeveer constant, met een redelijk strakke bovengrens. Uw cumulatieve opslaguitgaven groeien lineair. Dit is een typisch scenario voor een reeks uitvoerbare bestanden en scripts.
- In een gebruikssituatie waarbij u voortdurend nieuwe gegevens genereert met een constante snelheid, stijgen uw maandelijkse opslagkosten lineair. Uw cumulatieve opslagkosten worden kwadratisch verhoogd.
- In een use-geval waarbij de snelheid van het genereren van gegevens zelf lineair groeit, groeien uw maandelijkse opslagkosten kwadratisch en worden uw cumulatieve opslagkosten kubisch.
- In een gebruikssituatie waarin de snelheid van gegevensgeneratie exponentieel groeit, groeien zowel uw maandelijkse gegevensopslagkosten als uw cumulatieve gegevensopslagkosten exponentieel.
- 3 Onderzoek of objectversie-indeling zinvol is voor uw doelen.[24]
- Met objectversie kunt u oudere versies van een bestand bewaren. Een voordeel is dat u een oudere versie opnieuw kunt bezoeken.
- Als u objectversiebeheer gebruikt, kunt u dit combineren met levenscyclusbeleid om oudere versies dan een bepaalde leeftijd (of niet de huidige versie) te beëindigen.
- Als u gebruikmaakt van objectversionering, houd er dan rekening mee dat alleen het vermelden van bestanden (met behulp van aws s3 ls of de online-interface) ertoe leidt dat u de totale gebruikte opslag onderschat, omdat u wordt betaald voor oudere versies die niet in de lijst zijn opgenomen.
- 4 Verken het levenscyclusbeleid voor uw gegevens.
- U kunt beleidsregels instellen om automatisch gegevens in bepaalde buckets te verwijderen, of zelfs met specifieke voorvoegsels in buckets, die meer dan een bepaald aantal dagen oud zijn. Dit kan u helpen uw S3-kosten beter onder controle te houden en u ook helpen te voldoen aan verschillende privacy- en gegevensbeleidsregels. Merk op dat sommige wetten en richtlijnen voor het bewaren van gegevens mogelijk kunnen zijn vereisen u om gegevens voor een minimumtijd te handhaven; deze stellen een lagere tijdslimiet in waarna u gegevens in uw levenscyclusbeleid kunt verwijderen. Andere beleidsregels of wetten vereisen mogelijk dat u gegevens binnen een bepaalde periode verwijdert; deze stellen een bovengrens aan de tijd waarna gegevens in uw levenscyclusbeleid moeten worden verwijderd.
- Met een levenscyclusbeleid voor verwijdering, verandert de manier waarop uw kosten groeien veel. Met een constante stroom binnenkomende gegevens blijven uw maandelijkse opslagkosten constant in plaats van lineair groeien, omdat u tot nu toe alleen een bewegend gegevensvenster bewaart in plaats van alle gegevens. Zelfs als de omvang van inkomende gegevens lineair groeit, groeien uw maandelijkse opslagkosten alleen lineair in plaats van kwadratisch. Hiermee kunt u uw infrastructuurkosten aan uw verdienmodel koppelen: als uw maandelijkse inkomsten ongeveer evenredig zijn aan de snelheid waarmee u gegevens ontvangt, is uw opslagmodel schaalbaar.
- Een technische beperking: u kunt geen twee beleidsregels instellen met dezelfde bucket waarbij een prefix een subset van de andere is. Houd dit in gedachten terwijl u nadenkt over het opslaan van uw S3-gegevens.
- Naast het levenscyclusbeleid voor verwijdering, kunt u ook beleidsregels instellen om de gegevens te archiveren (d.w.z. het omzetten van standaardopslag naar Glacier), waardoor de opslagkosten worden verlaagd. Glacier hanteert echter een minimum bewaartermijn van 90 dagen: u betaalt 90 dagen opslag in Glacier, zelfs als u ervoor kiest om het voor die tijd te verwijderen. Daarom is het waarschijnlijk geen goed idee om naar Glacier te gaan als u binnenkort wilt verwijderen.
- U kunt ook een levenscyclusbeleid hebben om gegevens in S3 (standaardopslag) te converteren naar S3 - IA. Dit beleid is ideaal voor gegevens waarvan u verwacht dat ze vaak worden geopend in de onmiddellijke nasleep van de aanmaak ervan, maar niet vaak daarna. Bestanden in IA hebben een minimale objectgrootte (u betaalt een bestandsgrootte van 128 kB voor kleinere bestanden dan dat) en een minimale bewaarperiode van 30 dagen.
- Merk op dat overgangen in de levenscyclus zelf geld kosten en het is vaak beter om objecten rechtstreeks in de gewenste opslagklasse te maken in plaats van deze over te zetten. U moet de berekeningen voor uw use-case uitvoeren om te weten of en wanneer lifecycle-transitie zinvol is.
- 5 Gebruik de volgende heuristieken om de beste opslagklasse te bepalen op basis van uw use-case. Terwijl we praten alsof we te maken hebben met een enkel bestand, denken we echt aan een opstelling waarbij dit afzonderlijk en onafhankelijk gebeurt voor een groot aantal bestanden.
- De eerste stap bij het bepalen van de juiste opslagklasse is om een schatting te krijgen voor uw bestandsgrootte, bewaartermijn, verwachte aantal toegangen (evenals hoe dat aantal varieert in de loop van de tijd op basis van leeftijd) en de maximale hoeveelheid tijd die u kunt wachten wanneer je toch iets nodig hebt. U kunt al deze parameters als parameters gebruiken in een formule die de verwachte kosten berekent voor het gebruik van elke opslagklasse. De formule wordt nogal gecompliceerd.
- Houd er rekening mee dat exacte drempels hiervoor kunnen variëren op basis van de huidige prijzen in uw regio. Prijzen variëren per regio en blijven in de loop van de tijd veranderen. Met name de volgende kwestie: opslagprijzen voor elke opslagklasse, prijsaanvragen voor elke opslagklasse, ophaalprijzen voor elke opslagklasse en vereisten voor minimale grootte en minimale bewaarperiode. Met deze voorbehouden zijn de heuristieken hieronder weergegeven.
- Als u gegevens twee weken of minder wilt bewaren, verdient standaardopslag de voorkeur zowel voor IA als voor Glacier-opslag. De reden is dat de minimale bewaartermijnen (30 dagen voor IA, 90 dagen voor Glacier) de kostenvoordelen annuleren (ten hoogste tweemaal voor IA, ongeveer zes keer voor Glacier) na twee weken of minder.
- Als uw bestandsgrootte 64 kB of minder is, verslaat de standaardopslag altijd IA-opslag. Dat komt omdat de vereiste minimumgrootte van IA (128 KB) het kostenvoordeel teniet doet (maximaal dubbel).
- Als u van plan bent om eenmaal per maand of vaker toegang te krijgen tot elk bestand, wint de standaardopslag ten opzichte van zowel IA als Glacier. Dat komt omdat de extra kosten van zelfs één gegevensherstel de maandelijkse opslagbesparing vernietigen.
- Stel dat u gegevens heeft die u in eerste instantie een maand lang in de standaardopslag wilt bewaren, waarna u het een maand of langer kunt verplaatsen naar IA, omdat u verwacht dat u daarna helemaal geen toegang meer tot IA hoeft te hebben. Het is logisch om het alleen naar IA te verplaatsen als het totale aantal megabyte-maanden in IA-staat per bestand ten minste 1 is. Dat komt omdat de overgangskosten van de overgang naar IA moeten worden overbrugd door de kostenbesparing. Als u bijvoorbeeld de gegevens een maand langer wilt bewaren, moet de bestandsgrootte ten minste 1 MB zijn, zodat dit een zinvolle uitgave is. Let op de minimale periode van 30 dagen maakt overgangen voor kortere tijden zelfs minder de moeite waard.
- Op dezelfde manier is de breakeven voor migratie naar Glacier ongeveer 2,5 megabyte-maanden voor elk bestand. Merk echter op dat de minimum retentieperiode van 90 dagen in Glacier zaken bemoeilijkt; Als u van plan bent om gedurende een maand te profiteren van het verplaatsen van gegevens naar Glacier, moet de bestandsgrootte 7,5 MB of meer zijn.
- Als u verwacht dat u geen toegang tot de inhoud nodig hebt na het schrijven naar S3, is de optimale strategie meestal standaard of Glacier, waarbij de afweging afhankelijk is van de bewaartermijn. Er zit echter een goede plek tussen, waarbij IA de beste optie is (bijvoorbeeld 128 KB opslaan voor een maand). Om dit te illustreren, is hieronder een afbeelding voor het eenvoudige geval waarin u een enkel bestand van een vaste schijf moet bewaren. grootte voor een vaste hoeveelheid tijd, met nul verwachte toegangen nadat het is opgeslagen. De tijd in maanden staat op de horizontale as en de bestandsgrootte in GB bevindt zich op de y-as. Een punt is blauw, rood of geel gekleurd, afhankelijk van of de optimale opslagklasse vanuit een kostenperspectief standaard, IA of Glacier is. We gebruiken de kosten zoals in de US Standard-regio in december 2016.
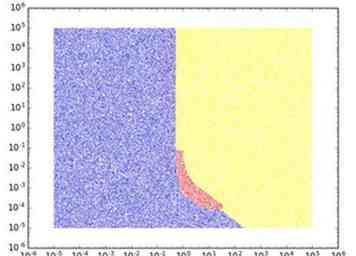
- Naarmate u het verwachte aantal toegangen tot de gegevens verhoogt, wordt de standaard optimaal voor steeds meer gebruiksgevallen (dat wil zeggen voor grotere gegevensgroottes en voor langere bewaartermijnen). IA wordt ook optimaal in gevallen waarin Glacier eerder optimaal was geweest. Met andere woorden, standaard neemt het over van IA en IA neemt het over van Glacier.
- 6 Gebruik de volgende common-sense benchmarks op basis van uw opslaggebruik. Dit helpt u een idee te krijgen van hoeveel u kunt verwachten in opslagkosten.
- Als u live een statische website of afbeeldingen gebruikt: de opslagkosten bedragen waarschijnlijk enkele centen, met details die afhankelijk zijn van de grootte van uw site. De belangrijkste kosten van het bedienen van een live-site zijn de prijs en overdrachtskosten voor aanvragen.
- Als u een datameer opslaat waarbij de door de gebruiker gegenereerde stream web- of app-activiteit is (dat wil zeggen webaanvraaglogboeken): een individuele webaanvraaglogregel kan in maximale grootte variëren van 1 kB (als u alle standaardkopteksten en velden) tot 10 kB (als u ook perifere informatie over de gebruiker en de context opneemt). Als u een miljoen webverzoeken per maand ontvangt en oude logboeken voor webaanvragen een maand bewaard, vertaalt dit zich ergens tussen 1 GB en 10 GB opslag, wat tussen 2,3 cent en 40,5 cent is in maandelijkse opslagkosten. De kosten schalen lineair, zowel met uw verkeer en met uw beslissing over hoe lang op te slaan. Bijvoorbeeld, met een miljard webverzoeken per maand en het opslaan van gegevens voor een jaar, schieten uw maandelijkse gegevensopslagkosten omhoog naar ergens tussen $ 276 en $ 4860. Het gebruik van binaire formaten en zippen / comprimeren kan de kosten omlaag brengen.
- Als u archieven van afbeeldingen en videobeelden opslaat: Als u bijvoorbeeld een televisienetwerk bent dat regelmatig beelden maakt en oude archieven van oude beelden beschikbaar wil houden voor het geval dit later relevant wordt. Dit is een use-case waarbij de totale opslagruimte vrij groot kan zijn. Bijvoorbeeld, met 10 uur aan dagelijkse videobeelden, zou je elke dag iets in het bereik van 100 GB (ongecomprimeerd) kunnen toevoegen. Als je dit beeldmateriaal het eerste jaar in standaardopslag opslaat en vervolgens negen jaar naar Glacier archiveert, zouden je totale gegevens 365 TB (36,5 TB in standaardopslag) bedragen en zouden je maandelijkse S3-opslagkosten (vóór compressie) ongeveer $ 2200 (twee derde voor Glacier, een derde voor standaard opslag). Compressie van verschillende soorten kan de opslagkosten verlagen met een factor variërend van 2 tot 10.
- Het is leerzaam om te kijken naar de rekeningen van sommige krachtige S3-gebruikers om een idee te krijgen van hoeveel een factuur kan variëren.
- Er werd gemeld dat Dropbox 500 petabytes aan gegevens in S3 zou hebben voordat het naar zijn eigen servers zou worden verplaatst[25] Bij de huidige online genoteerde prijzen zou dat ongeveer $ 10,5 miljoen per maand kosten.Hoewel Dropbox waarschijnlijk een aanzienlijke korting kreeg en voordelen behaalde met datadeduplicatie en compressie, was de rekening waarschijnlijk nog steeds minstens honderdduizenden dollars per maand.
- Een ander extreem voorbeeld van een grote gebruiker is DigitalGlobe, dat 100 PB hoge-resolutie satellietbeelden naar S3 verplaatst.[26]
- Pinterest meldde dat het 20 terabytes aan gegevens per dag toevoegt, wat betekent dat in de standaardopslag hun maandelijkse factuur elke dag met $ 600 / maand zou stijgen. Als deze toevoeging van gegevens tien jaar duurt, hebben ze een totale opslagcapaciteit van ongeveer 75 PB en een maandelijkse factuur in de orde van grootte van honderdduizenden dollars.
- Behalve deze extreem gebruikssituaties hebben zelfs enkele van 's werelds grootste bedrijven redelijk lage S3-facturen. Eind 2013 rapporteerde Airbnb bijvoorbeeld 50 TB aan thuisfoto's met een hoge resolutie, een bedrag dat tegen de huidige prijzen ongeveer $ 1150 per maand zou kosten.[27]

Deel vier van de zes:
Gegevensoverdrachtkosten optimaliseren
- 1 Als u S3 gebruikt voor live-inhoud, plaatst u deze achter een CDN zoals Amazon CloudFront, CloudFlare of MaxCDN.
- Het CDN heeft een groot aantal randlocaties in verschillende delen van de wereld, meestal variërend van tientallen tot honderden.
- Het verzoek van de gebruiker om de pagina wordt gerouteerd naar de dichtstbijzijnde CDN-randlocatie. Die randlocatie controleert vervolgens of deze een bijgewerkte kopie van de resource heeft. Als dit niet het geval is, wordt het opgehaald van S3. Anders dient het de kopie die het heeft.
- Het resultaat: eindgebruikers zien een hogere beschikbaarheid en een lagere latentie (omdat de bronnen worden aangeboden vanaf een locatie die fysiek dicht bij hen ligt) en het aantal verzoeken en de hoeveelheid gegevensoverdracht van S3 wordt laag gehouden. Expliciet is het aantal verzoeken begrensd door (aantal randlocaties) X (aantal bestanden) als u nooit bestanden bijwerkt; als u bestanden bijwerkt, moet u ook vermenigvuldigen met het aantal bestandsupdates.
- 2 Begrijp het belangrijkste co-locatie voordeel van EC2 / S3. Als uw primaire gebruik voor S3 is om gegevens te lezen en te schrijven naar EC2-exemplaren (dat wil zeggen, elk van de andere use-cases dan het live-server-exemplaar), dan is dit voordeel het beste te behalen als uw S3-bucket zich in dezelfde AWS-regio bevindt als de EC2-instanties die deze lezen of ernaar schrijven. Dit heeft verschillende voordelen:
- Lage latentie (minder dan een seconde)
- Hoge bandbreedte (meer dan 100 Mbit / seconde): houd er rekening mee dat de bandbreedte tussen de verschillende regio's in de VS vrij goed is, dus dit is geen belangrijk probleem als al uw regio's in de VS zijn, maar het kan aanzienlijk zijn tussen de VS en EU, EU en Azië-Pacific, of de VS en Azië-Pacific.
- Geen kosten voor gegevensoverdracht (u betaalt echter nog steeds de prijs van het verzoek)[14]
- 3 Bepaal de locatie (AWS-regio) van uw S3-bucket (s).
- Als u EC2-subsystemen uitvoert die van de S3-buckets lezen of naar deze schrijven: Zoals opgemerkt in stap 1, helpt colocatie van S3 en EC2, voor zover haalbaar, met bandbreedtet, latency en gegevensoverdrachtskosten. Daarom is een belangrijke overweging bij het lokaliseren van uw S3-bucket: waar verwacht u de EC2-instanties te hebben die interactie hebben met deze S3-bucket? Als de EC2-exemplaren meestal achterliggende exemplaren zijn, moet u rekening houden met de kosten van deze instanties. Als dit frontend-instanties zijn, moet u overwegen naar welke regio's u het meeste verkeer wilt ontvangen. Over het algemeen moet u van EC2-instantieoverwegingen verwachten dat ze belangrijker zijn dan S3-overwegingen bij het bepalen van de regio. Het is dus meestal logisch om eerst te beslissen waar u verwacht dat uw EC2-subsysteemcapaciteit zal zijn en vervolgens uw S3-buckets daar te hebben. Over het algemeen zijn de S3-kosten lager in dezelfde regio's als EC2-instanties, dus dit creëert gelukkig geen conflict.
- Als er andere AWS-services zijn die u moet hebben, maar niet in alle regio's beschikbaar zijn, kan dit ook uw regiokeuze beperken.
- Als u regelmatig bestanden van uw thuiscomputer naar S3 uploadt, kunt u overwegen om een bucket in een regio dichter bij uw huis te krijgen om de uploadlatentie te verbeteren. Dit zou echter een ondergeschikte overweging moeten zijn ten opzichte van de anderen.
- Als u verwacht S3 te gebruiken voor live-weergave van statische afbeeldingen, bepaalt u de locatie op basis van waar u uw verkeer vandaan wilt halen.
- In sommige gevallen beperkt het beleid dat u op basis van wetgeving of contract moet volgen uw regiokeuze voor S3-gegevensopslag. Houd er ook rekening mee dat de fysieke locatie van uw S3-bucket invloed kan hebben op wat overheden Amazon wettelijk kunnen dwingen om uw gegevens vrij te geven (hoewel dergelijke gevallen vrij zeldzaam zijn).[28]
- 4 Onderzoek of cross-regio-replicatie logisch is voor uw bucket.[29] Reproductie in verschillende regio's tussen emmers in verschillende regio's synchroniseert automatisch up-upgegevens naar gegevens in één bucket met gegevens in andere buckets. De wijziging kan niet onmiddellijk plaatsvinden en met name grote bestandsveranderingen worden beperkt door bandbreedtebeperkingen tussen regio's. Houd rekening met de volgende voor- en nadelen van replicatie tussen regio's.[5]
- U betaalt meer in S3-opslagkosten, omdat dezelfde gegevens in meerdere regio's worden gespiegeld.
- U betaalt in S3 <-> S3 kosten voor gegevensoverdracht. Als de gegevens echter worden gelezen of geschreven door EC2-instanties in meerdere regio's, kan dit worden gecompenseerd door besparingen in de S3 -> EC2-gegevensoverdrachtskosten. De belangrijkste manier waarop dit kan helpen is als u dezelfde S3-gegevens in EC2-exemplaren in veel verschillende regio's laadt. Stel dat u elk 100 exemplaren in Oost- en West-Amerika hebt waar u dezelfde gegevens uit een S3-bucket in US West moet laden. Als u deze bucket niet repliceert in US-Oosten, betaalt u voor de overdrachtskosten van de 100 gegevensoverdrachten van de S3-bucket naar de US East-machines. Als u de bucket in US East repliceert, betaalt u slechts één keer voor de kosten voor gegevensoverdracht.
- Cross-regio replicatie heeft dus veel zin voor uitvoerbare bestanden, scripts en relatief statische gegevens, waarbij u waarde hecht aan regio-overschrijdende redundantie, waar updates van de gegevens zeldzaam zijn en waar de meeste gegevensoverdracht plaatsvindt in de S3 -> EC2 richting. Een ander voordeel is dat als deze gegevens over regio's worden gerepliceerd, het veel sneller is om nieuwe exemplaren op gang te brengen, waardoor flexibelere EC2-instance-architecturen mogelijk worden.
- Voor logging-applicaties (waar data door veel frontend-instanties wordt gelezen en op een centrale locatie in S3 moet worden ingelogd) is het beter om een service zoals Kinesis te gebruiken om datastreams over regio's te verzamelen in plaats van replicatie van S3-buckets met verschillende regio's .
- Als u S3 gebruikt voor het live weergeven van statische afbeeldingen op een website, kan het gebruik van kruisregio-replicatie zinvol zijn als uw websiteverkeer globaal is en het snel laden van afbeeldingen belangrijk is.
- 5 Als u regelmatige updates synchroniseert naar bestaande bestanden, kiest u een mapstructuur waarin u de synchronisatiefunctie van de AWS CLI kunt gebruiken.
- De opdracht "aws s3 sync" gedraagt zich als rsync, maar kan alleen op het niveau van een map worden uitgevoerd. Houd daarom uw mappenstructuur zo dat u deze opdracht kunt gebruiken.
- 6 Houd rekening met de volgende heuristieken voor het schatten van transactiekosten.
- Voor een live-serverende statische website is de maandelijkse gegevensoverdracht, zonder CDN, gelijk aan de totale verkeerstijden van elke bezochte pagina (inclusief afbeeldingen en andere bronnen die op de pagina zijn geladen). Voor bijvoorbeeld een miljoen pageviews en een gemiddelde paginagrootte van 100 kB is de totale gegevensuitgifte 100 GB, wat $ 9 per maand kost.
- Voor een live-serverende statische website achter een CDN legt de CDN een bovengrens op voor de totale gegevensoverdracht. Als u de gegevens helemaal niet bijwerkt, zodat het CDN een eigen cache bevat, wordt de totale gegevensoverdracht beperkt door het product van de totale grootte van uw website en het aantal randlocaties van het CDN, ongeacht het verkeer volume. Als uw site bijvoorbeeld in totaal 1000 pagina's van 100 KB heeft, is de totale grootte 100 MB. Als er 100 randlocaties zijn, geeft dit een totale gegevensoverdrachtlimiet van 10 GB per maand, of een kostenlimiet van 90 cent per maand. Als u echter een aantal bestanden bijwerkt, moet u elk bestand na elke update opnieuw tellen.
- De mate waarin CDN's besparen ten opzichte van geen CDN hebben, hangt af van de diversiteit van toegang tot uw inhoud en ook van de geografische spreiding van toegang. Als uw inhoud wordt gebruikt in één geografische regio, bespaart u meer. Als mensen een klein aantal pagina's op uw site openen, bespaart u meer. Als mensen binnen elke regio een klein aantal pagina's op uw site openen (zelfs als de pagina's per regio verschillen), bespaart u meer. CDN-besparingen kunnen variëren van 50% tot 99%.[10]
Vijfde deel van de zes:
Optimalisatie van de kosten als gevolg van prijsaanvragen
- 1 Als aanvraagprijs een belangrijke zorg is, bewaar uw gegevens dan in de standaardopslag. Zie deel 3, stap 5 voor meer informatie.
- 2 Als u live een statische site of statische afbeeldingen of video via S3 serveert, plaatst u deze achter een CDN. Dit is om dezelfde redenen als die besproken in Deel 4, Stap 1.
- 3 Als u S3 gebruikt als een gegevensopslag voor het opzoeken van sleutelwaarden, moet u de prijzen van PUT-aanvragen inruilen tegen de prijs van gegevensoverdracht bij het bepalen van de grootte van de bestanden die u nodig hebt om uw gegevens te vernietigen.
- Als u de gegevens verdeelt in een groot aantal kleine bestanden, moet u een groot aantal PUT's gebruiken om de gegevens in te voegen, maar elke zoekopdracht is sneller en gebruikt minder gegevensoverdracht, omdat u een kleiner bestand van S3 moet lezen.
- Aan de andere kant, als u de gegevens in een klein aantal grote bestanden partitioneert, hebt u een klein aantal PUT's nodig, maar elke toegang kost veel in kosten voor gegevensoverdracht (omdat u een groot bestand moet lezen).
- De afweging gebeurt meestal ergens in het midden. Wiskundig gezien is het aantal bestanden dat u moet gebruiken de vierkantswortel van de verhouding van een term voor gegevensoverdrachtskosten tot een PUT-kostenterm.
- 4Over het algemeen is het gebruik van een kleiner aantal middelgrote bestanden beter voor een datameer.
- 5 Als u gegevens onderverdeelt in bestanden, gebruikt u een klein aantal middelgrote bestanden (ergens tussen 1 MB en 100 MB) om aanvraagprijs en overbelasting tot een minimum te beperken.
- Een kleiner aantal grotere bestanden vermindert het aantal verzoeken dat nodig is om de gegevens op te halen en te laden en om de gegevens te schrijven.
- Aangezien er een kleine hoeveelheid latentie is gekoppeld aan elk gelezen bestand, zullen gedistribueerde computerprocessen (zoals op Hadoop gebaseerde of op Apache Spark gebaseerde processen) dat gelezen bestanden over het algemeen sneller gaan met een klein aantal middelgrote bestanden dan met een grote aantal kleine bestanden.
- Hoe minder uw totale aantal bestanden, des te minder kost het is om query's uit te voeren die willekeurige reguliere expressies proberen te evenaren.
- Een belangrijk voorbehoud is dat in veel gevallen het natuurlijke uitvoertype een groot aantal kleine bestanden is. Dit geldt voor de uitvoer van gedistribueerde computerwerklasten, waarbij elk knooppunt in het cluster een klein bestand berekent en uitvoert. Het is ook waar als gegevens in realtime worden uitgeschreven en we de gegevens binnen een kort tijdsinterval willen wegschrijven. Als u verwacht deze gegevens herhaaldelijk te lezen en te verwerken, kunt u overwegen om de gegevens samen te voegen in grotere bestanden. Voor gegevens die in realtime binnenkomen, kunt u overwegen om streaming-services zoals Kinesis te gebruiken om gegevens te verzamelen voordat u deze naar S3 gaat schrijven.
- 6 Als u grote onverwachte verzoekkosten ziet, zoekt u naar malafide processen waarbij regex-overeenkomsten worden toegepast. Zorg ervoor dat elke regex-overeenkomst jokertekens zo dicht mogelijk bij het einde van het bestand gebruikt.
- 7 Houd rekening met de volgende heuristieken voor aanvraagkosten.
- Aanvraagkosten moeten tussen 0% en 20% van de opslagkosten bedragen.Als deze hoger zijn, overweeg dan of u de juiste opslagklasse gebruikt, de gegevens in de juiste grootten scherpt of onnodige of inefficiënte bewerkingen uitvoert. Controleer ook op onnodige lifecyle-overgangen en op bedrieglijke regex-afstemmingsprocessen.
- Verzoeken om kosten moeten minder zijn dan overdrachtskosten als uw gegevens voornamelijk worden verzonden naar externe AWS (als uw gegevens binnen dezelfde AWS-regio worden verzonden, mogen er geen kosten voor gegevensoverdracht zijn, dus dit is niet van toepassing, omdat positief terwijl de overdrachtskosten nul zijn).
Deel zes van de zes:
Monitoring en debugging
- 1 Stel monitoring in voor uw S3-kosten.
- Uw AWS-account heeft toegang tot de factureringsgegevens die de volledige uitsplitsing van de kosten weergeven. Stel een factureringsmelding in zodat de gegevens naar Amazon CloudWatch worden verzonden. U kunt dan meer meldingen instellen met behulp van CloudWatch.[30] CloudWatch-gegevens worden om de paar uur aangeboden als gegevenspunten, maar bevatten geen gedetailleerde uitsplitsing langs alle relevante dimensies.
- U kunt op elk gewenst moment gedetailleerde uitsplitsing per uur en servicetype downloaden van uw rootaccount. Deze gegevens zijn meestal 24-48 uur te laat, d.w.z. u zult geen informatie zien voor de meest recente 24-48 uur. Voor S3 kunt u in een spreadsheet- of CSV-indeling de gegevens downloaden met uitsplitsing naar uur, bucket, regio en bewerkingstype (GET, POST, LIST, PUT, DELETE, HEADOBJECT, of wat uw operaties ook zijn).
- 2 Schrijf scripts om gemakkelijk leesbare dagelijkse rapporten van uw kosten op verschillende manieren opgesplitst te krijgen.
- Op het hoogste niveau wilt u misschien een uitsplitsing van uw kosten rapporteren tussen opslag, overdracht en prijsaanvraag.
- Binnen elk van deze kunt u de kosten wellicht verder verlagen op basis van de opslagklasse (Standard, RRS, IA en Glacier).
- Binnen aanvraagprijs, wilt u misschien kosten afbreken door het type bewerking (GET, POST, LIST, PUT, DELETE, HEADOBJECT, of wat uw operaties ook zijn).
- U kunt ook een uitsplitsing per bucket opgeven.
- Als algemene regel, moet u het aantal dimensies bepalen dat u inzoomt door het gemak van snel begrip in te ruilen tegen voldoende granulariteit. Een over het algemeen goede afweging is om drilldowns in één dimensie tegelijk op te nemen (bijvoorbeeld één drilldown per bucket, één drilldown op opslag versus transfer versus request-prijzen, één drilldown op opslagklasse) in uw dagelijkse rapport en alleen verder te analyseren als iets ongewoon lijkt.
- 3 Bouw een verwacht kostenmodel en gebruik uw script om verschillen tussen de werkelijke kosten en uw model te identificeren.
- Zonder een model van welke kosten moeten Het is moeilijk om de kosten te bekijken en te weten of ze ongelijk hebben.
- Het proces van het bouwen van een kostenmodel is een goede oefening om uw architectuur duidelijk te verwoorden en mogelijk te denken aan verbeteringen, zelfs zonder te kijken naar het patroon van de werkelijke kosten.
- 4 Debuggen hoge kosten.
- Als de boosdoener opslagkosten is, zie deel 3.
- Als de dader enorme kosten voor gegevensoverdracht heeft, raadpleegt u deel 4.
- Als de boosdoener de prijsstelling aanvraagt, zie deel 5.